2020年12月01日,IntelliJ IDEA 2020.3 正式发布,这是2020年的第三个里程碑版本。2020年其他两个版本可以参见IntelliJ IDEA 2020.2 稳定版发布 和 IntelliJ IDEA 2020.1 稳定版发布。本文主要介绍 IntelliJ IDEA 2020.3 的新功能。如果想及时了解Spark、Hadoop或者HBase相关的文章,欢迎关注微信公众号:iteblog_hadoop用户体验重新设置欢迎界面这个 w397090770 4年前 (2020-12-10) 1035℃ 0评论0喜欢
假设我们有个需求,需要解析文件里面的Json数据,我们的Json数据如下:[code lang="xml"]{"website": "www.iteblog.com", "email": "hadoop@iteblog.com"}[/code]我们使用play-json来解析,首先我们引入相关依赖:[code lang="xml"]<dependency> <groupId>com.typesafe.play</groupId> <artifactId>play-json_2.10</artifactId w397090770 7年前 (2017-08-02) 2866℃ 0评论16喜欢
本系列文章将展示ElasticSearch中23种非常有用的查询使用方法。由于篇幅原因,本系列文章分为六篇,本文是此系列的第二篇文章。欢迎关注大数据技术博客微信公共账号:iteblog_hadoop。《23种非常有用的ElasticSearch查询例子(1)》《23种非常有用的ElasticSearch查询例子(2)》《23种非常有用的ElasticSearch查询例子(3)》《23种非常有用 w397090770 8年前 (2016-08-16) 5568℃ 0评论6喜欢
写在前面的话,学Hive这么久了,发现目前国内还没有一本完整的介绍Hive的书籍,而且互联网上面的资料很乱,于是我决定写一些关于《Hive的那些事》序列文章,分享给大家。我会在接下来的时间整理有关Hive的资料,如果对Hive的东西感兴趣,请关注本博客。/archives/tag/hive的那些事在《Hive内置数据类型》文章中,我们提到了Hive w397090770 11年前 (2014-01-07) 139346℃ 1评论481喜欢
在 《如何在Spark、MapReduce和Flink程序里面指定JAVA_HOME》文章中我简单地介绍了如何自己指定 JAVA_HOME 。有些人可能注意到了,上面设置的方法有个前提就是要求集群的所有节点的同一路径下都安装部署好了 JDK,这样才没问题。但是在现实情况下,我们需要的 JDK 版本可能并没有在集群上安装,这个时候咋办?是不是就没办法呢?答案 w397090770 7年前 (2017-12-05) 2994℃ 0评论18喜欢
题目描述:给定a和n,计算a+aa+aaa+a...a(n个a)的和。输入:测试数据有多组,输入a,n(1<=a<=9,1<=n<=100)。输出:对于每组输入,请输出结果。样例输入:1 10样例输出:1234567900从题中就可以看出,当a = 9, n = 100的时候,一个int类型的数是存不下100位的数,所以不能运用平常的方法来求,下面介绍我的解法,我声明 w397090770 12年前 (2013-03-31) 4161℃ 0评论4喜欢
为了提高本博客的用户体验,我于去年七月写了一份代码,将博客与微信公共帐号关联起来(可以参见本博客),用户可以在里面输入相关的关键字(比如new、rand、hot),但是那时候关键字有限制,只能对文章的分类进行搜索。不过,今天我修改了自动回复功能相关代码,目前支持对任意的关键字进行全文搜索,其结果相关与调用 w397090770 9年前 (2015-11-07) 2109℃ 0评论8喜欢
近几年来,人工智能逐渐火热起来,特别是和大数据一起结合使用。人工智能的主要场景又包括图像能力、语音能力、自然语言处理能力和用户画像能力等等。这些场景我们都需要处理海量的数据,处理完的数据一般都需要存储起来,这些数据的特点主要有如下几点:大:数据量越大,对我们后面建模越会有好处;稀疏:每行 w397090770 6年前 (2018-11-22) 3296℃ 1评论10喜欢
Shark是一种分布式SQL查询工具,它的设计目标就是兼容Hive,今天就来总结一下Shark对Hive特性的兼容。 一、Shark可以直接部署在Hive的数据仓库上。支持Hive的绝大多数特性,具体如下: Hive查询语句,包括以下: SELECT GROUP_BY ORDER_BY CLUSTER_BY SORT_BY 支持Hive中所有的操作符: 关系运算符(=, ⇔, ==, <>, <, & w397090770 11年前 (2014-04-30) 7324℃ 1评论4喜欢
我们在接触Hadoop的时候,第一个列子一般是运行Wordcount程序,在Spark我们可以用Java代码写一个Wordcount程序并部署在Yarn上运行。我们知道,在Spark源码中就存在一个用Java编写好的JavaWordCount程序,源码如下:[code lang="JAVA"]package org.apache.spark.examples;import org.apache.spark.api.java.JavaPairRDD;import org.apache.spark.api.java.JavaRDD;import org.apac w397090770 11年前 (2014-05-04) 28313℃ 1评论19喜欢
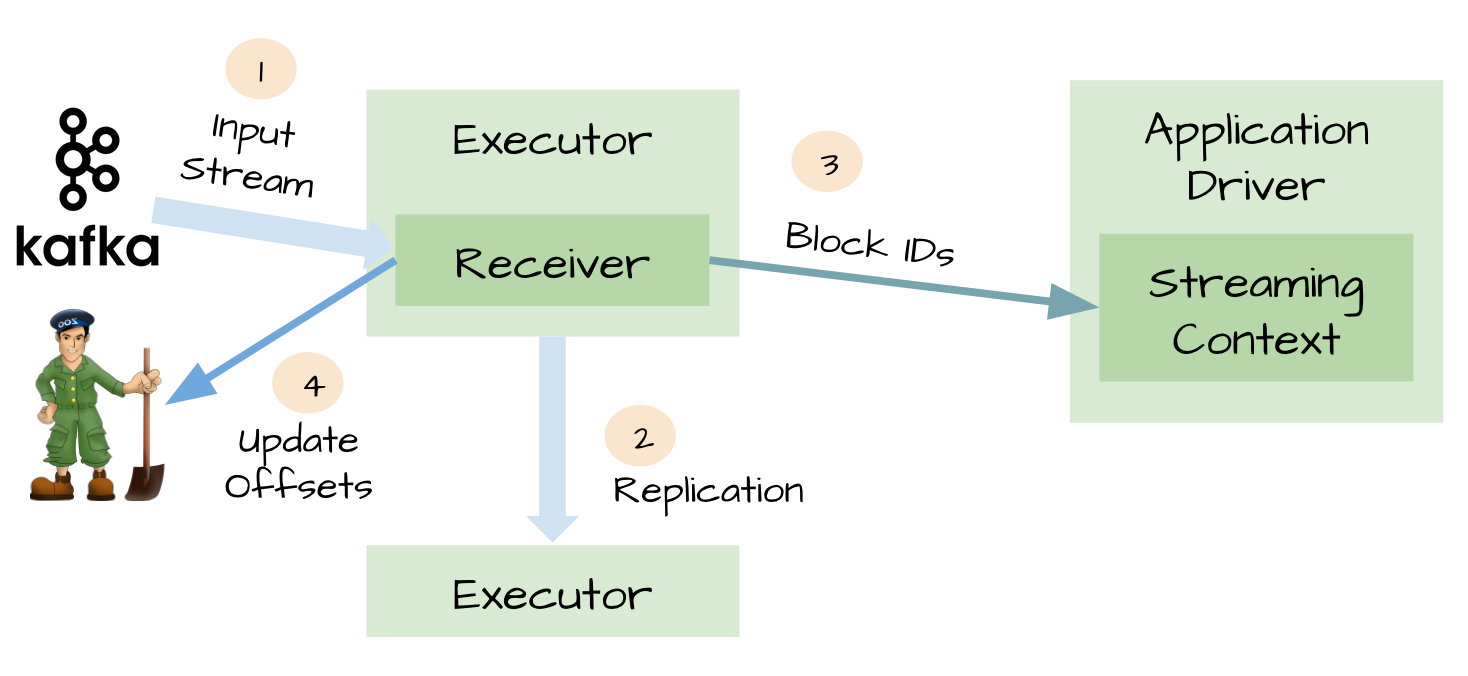
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制。为了体验这个关键的特性,你需要满足以下几个先决条件: 1、输入的数据来自可靠的数据源和可靠的接收器; 2、应用程序的metadata被application的driver持久化了(checkpointed ); 3、启用了WAL特性(Write ahead log)。 下面我将简单 w397090770 9年前 (2016-03-02) 17606℃ 16评论50喜欢
!! expr :逻辑非。%expr1 % expr2 - 返回 expr1/expr2 的余数.例子:[code lang="sql"]> SELECT 2 % 1.8; 0.2> SELECT MOD(2, 1.8); 0.2[/code]&expr1 & expr2 - 返回 expr1 和 expr2 的按位AND的结果。例子:[code lang="sql"]> SELECT 3 & 5; 1[/code]*expr1 * expr2 - 返回 expr1*expr2.例子:[code lang="sql"]> SELECT 2 * 3; 6[/code]+ w397090770 6年前 (2018-07-13) 16562℃ 0评论2喜欢
虽然在运行Hadoop的时候可以打印出大量的运行日志,但是很多时候只通过打印这些日志是不能很好地跟踪Hadoop各个模块的运行状况。这时候编译与调试Hadoop源码就得派上场了。这也就是今天本文需要讨论的。编译Hadoop源码 先说说怎么编译Hadoop源码,本文主要介绍在Linux环境下用Maven来编译Hadoop。在编译Hadoop之前,我们 w397090770 11年前 (2014-01-09) 19911℃ 0评论10喜欢
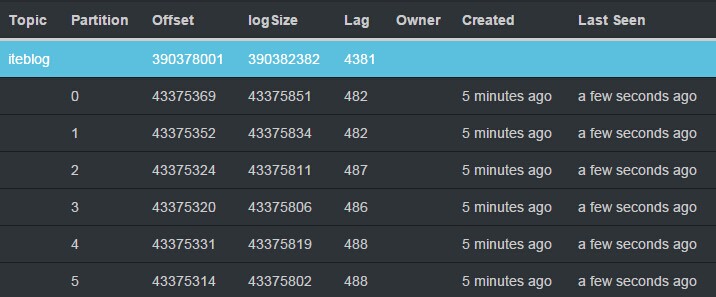
Apache Spark 1.3.0引入了Direct API,利用Kafka的低层次API从Kafka集群中读取数据,并且在Spark Streaming系统里面维护偏移量相关的信息,并且通过这种方式去实现零数据丢失(zero data loss)相比使用基于Receiver的方法要高效。但是因为是Spark Streaming系统自己维护Kafka的读偏移量,而Spark Streaming系统并没有将这个消费的偏移量发送到Zookeeper中, w397090770 9年前 (2015-06-02) 25661℃ 36评论22喜欢
Storm和Spark Streaming两个都是分布式流处理的开源框架。但是这两者之间的区别还是很大的,正如你将要在下文看到的。处理模型以及延迟 虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming w397090770 10年前 (2015-03-12) 16667℃ 1评论6喜欢
本次的分享内容分成四个部分:系统概述:认识kudu,理解Kudu的系统设计与定位生产实践:分享网易内部的典型使用场景遇到的问题:实际使用过程中遇到的问题和问题的排障过程功能展望:对Kudu功能特性的展望Kudu定位与架构Kudu是一个存储引擎,可以接入Impala、Presto、Spark等Olap计算引擎进行数据分析,容易融入Hadoop社区 w397090770 3年前 (2021-07-17) 284℃ 0评论1喜欢
本课程是Scala语言的入门课程,面向没有或仅有少量编程语言基础的同学,当然,具有一定的Java或C、C++语言基础将有助于本课程的学习。在本课程内,将更注重scala的各种语言规则与简单直接的应用,而不在于其是如何具体实现,通过学习本课程能具备初步的Scala语言实际编程能力。 此视频保证可以全部浏览,百度网盘 w397090770 10年前 (2015-03-21) 21924℃ 6评论46喜欢
一直运行的Spark Streaming程序如何关闭呢?是直接使用kill命令强制关闭吗?这种手段是可以达到关闭的目的,但是带来的后果就是可能会导致数据的丢失,因为这时候如果程序正在处理接收到的数据,但是由于接收到kill命令,那它只能停止整个程序,而那些正在处理或者还没有处理的数据可能就会被丢失。那我们咋办?这里有两 w397090770 8年前 (2017-03-01) 8857℃ 1评论11喜欢
在Debian平台,请输入以下的命令[code lang="JAVA"]$ sudo vi /etc/apt/sources.list[/code]在里面加入下面的一行[code lang="JAVA"]deb http://ftp.us.debian.org/debian/ squeeze main non-free[/code]然后保存退出(:wq)之后,执行下面的命令[code lang="JAVA"]$ sudo apt-get update[/code]安装Java执行环境运行下面命令[code lang="JAVA"]$ sudo apt-get install sun-java6-jre[/ w397090770 11年前 (2013-10-21) 6163℃ 2评论3喜欢
这几天在集群上部署了Shark 0.9.1,我下载的是已经编译好的,Hadoop版本是2.2.0,下面就总结一下我在安装Shark的过程中遇到的问题及其解决方案。一、YARN mode not available ?[code lang="JAVA"]Exception in thread "main" org.apache.spark.SparkException: YARN mode not available ? at org.apache.spark.SparkContext$.org$apache$spark$SparkContext$$createTaskScheduler(SparkContext. w397090770 11年前 (2014-05-05) 16048℃ 3评论4喜欢
在使用 Apache Spark 的时候,作业会以分布式的方式在不同的节点上运行;特别是当集群的规模很大时,集群的节点出现各种问题是很常见的,比如某个磁盘出现问题等。我们都知道 Apache Spark 是一个高性能、容错的分布式计算框架,一旦它知道某个计算所在的机器出现问题(比如磁盘故障),它会依据之前生成的 lineage 重新调度这个 w397090770 7年前 (2017-11-13) 10484℃ 0评论24喜欢
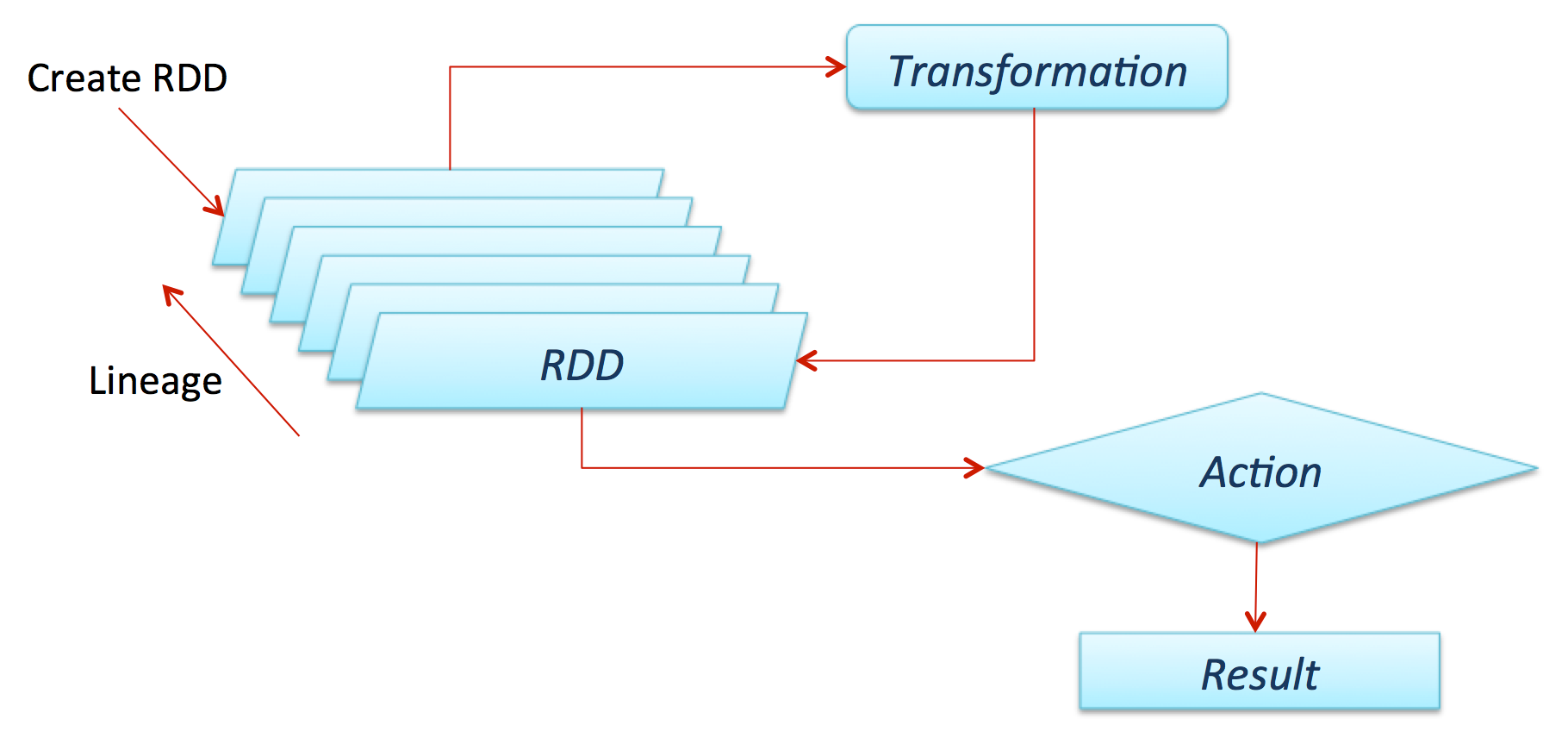
《Apache Spark快速入门:基本概念和例子(1)》 《Apache Spark快速入门:基本概念和例子(2)》五、弹性分布式数据集(Resilient Distributed Dataset,RDD) 弹性分布式数据集(RDD,从Spark 1.3版本开始已被DataFrame替代)是Apache Spark的核心理念。它是由数据组成的不可变分布式集合,其主要进行两个操作:transformation和action。Tr w397090770 9年前 (2015-07-13) 7663℃ 0评论8喜欢
上海Spark Meetup第四次聚会将于2015年5月16日在小沃科技有限公司(原中国联通应用商店运营中心)举办。本次聚会特别添加了抽奖环节,凡是参加了问卷调查并在当天到场的同学们都有机会中奖。奖品由英特尔亚太研发有限公司赞助。大会主题 Opening Keynote 沈洲 小沃科技有限公司副总经理,上海交通大学计算机专 w397090770 10年前 (2015-05-05) 3459℃ 0评论2喜欢
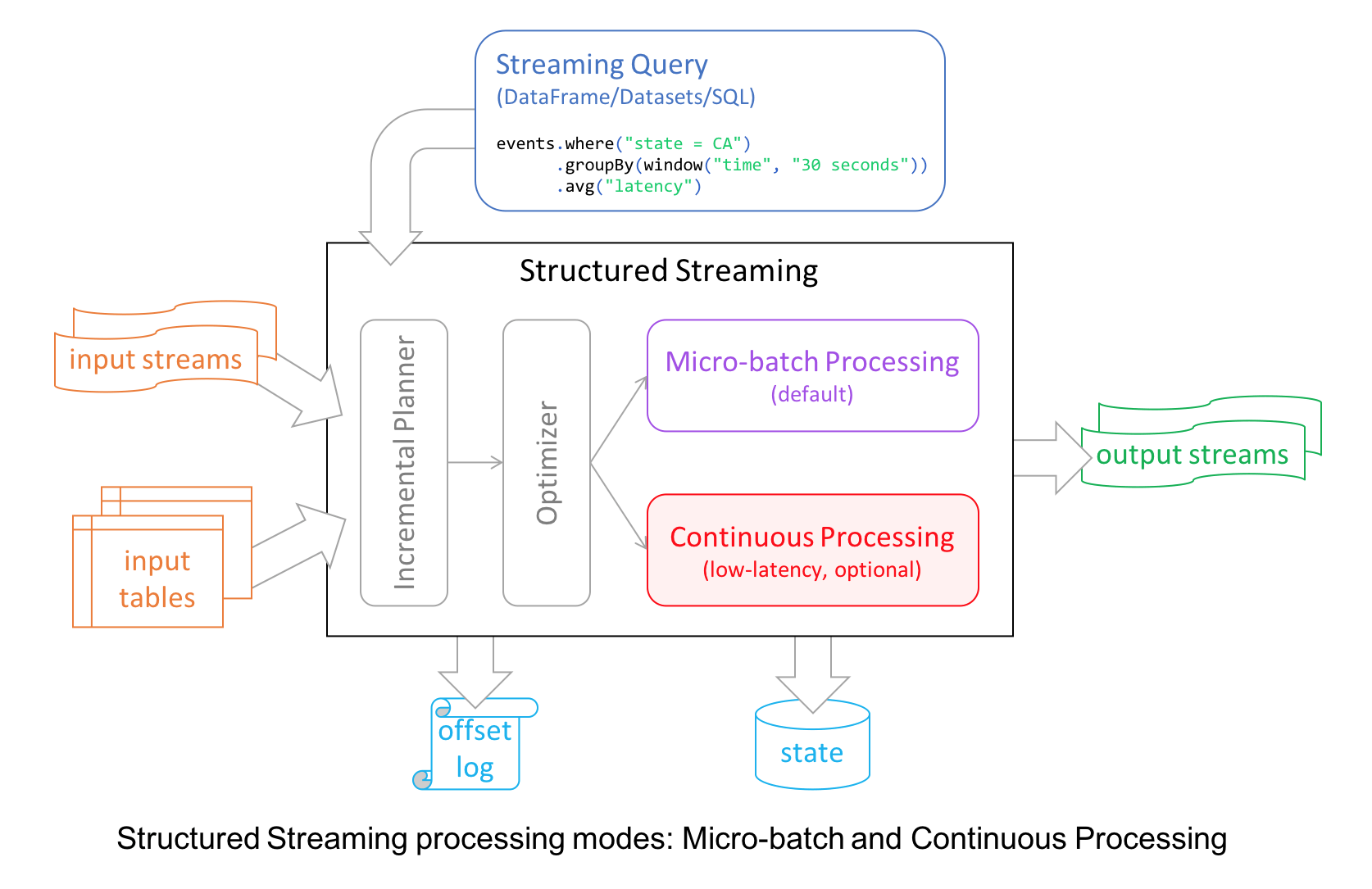
本文翻译自:Introducing Apache Spark 2.3为了继续实现 Spark 更快,更轻松,更智能的目标,Spark 2.3 在许多模块都做了重要的更新,比如 Structured Streaming 引入了低延迟的连续处理(continuous processing);支持 stream-to-stream joins;通过改善 pandas UDFs 的性能来提升 PySpark;支持第四种调度引擎 Kubernetes clusters(其他三种分别是自带的独立模式St w397090770 7年前 (2018-03-01) 7253℃ 3评论32喜欢
highlight.js是一款轻量级的Web代码语法高亮库,它主要有以下几个特点: (1)、支持118种语言(看这里https://github.com/isagalaev/highlight.js/tree/master/src/languages)和54中样式(看这里https://github.com/isagalaev/highlight.js/tree/master/src/styles); (2)、可以自动检测编程语言; (3)、同时为多种编程语言代码高亮; (4) w397090770 10年前 (2015-04-16) 14217℃ 0评论13喜欢
《Spark meetup(Beijing)资料分享》 《Spark meetup(杭州)PPT资料分享》 《北京第二次Spark meetup会议资料分享》 《北京第三次Spark meetup会议资料分享》 《北京第四次Spark meetup会议资料分享》 《北京第五次Spark meetup会议资料分享》》 《北京第六次Spark meetup会议资料分享》 下面是Spark meetup(Beijing)第 w397090770 10年前 (2014-08-29) 23964℃ 204评论16喜欢
摘要:本文是来自米哈游大数据部对于Flink在米哈游应用及实践的分享。 本篇内容主要分为四个部分: 1.背景介绍 2.实时平台建设 3.实时数仓和数据湖探索 4.未来发展与展望 作者:实时计算负责人 张剑 背景介绍 米哈游成立于2011年,致力于为用户提供美好的、超出预期的产品与内容。公司陆续推出了 w397090770 3年前 (2022-03-21) 1627℃ 1评论6喜欢
DataTables是一款非常简单的前端表格展示插件,它支持排序,翻页,搜索以及在客户端和服务端分页等多种功能。官方介绍:DataTables is a plug-in for the jQuery Javascript library. It is a highly flexible tool, based upon the foundations of progressive enhancement, and will add advanced interaction controls to any HTML table.它的数据源有很多种:主要有HTML (DOM)数据源 w397090770 10年前 (2015-01-28) 14708℃ 0评论16喜欢
如果你使用 Spark RDD 或者 DataFrame 编写程序,我们可以通过 coalesce 或 repartition 来修改程序的并行度:[code lang="scala"]val data = sc.newAPIHadoopFile(xxx).coalesce(2).map(xxxx)或val data = sc.newAPIHadoopFile(xxx).repartition(2).map(xxxx)val df = spark.read.json("/user/iteblog/json").repartition(4).map(xxxx)val df = spark.read.json("/user/iteblog/json").coalesce(4).map(x w397090770 6年前 (2019-01-24) 8154℃ 0评论12喜欢
Delta Lake 写数据是其最基本的功能,而且其使用和现有的 Spark 写 Parquet 文件基本一致,在介绍 Delta Lake 实现原理之前先来看看如何使用它,具体使用如下:[code lang="scala"]df.write.format("delta").save("/data/iteblog/delta/test/")//数据按照 dt 分区df.write.format("delta").partitionBy("dt").save("/data/iteblog/delta/test/" w397090770 5年前 (2019-09-10) 2186℃ 0评论2喜欢